Service Discovery in Microservice Architecture

Table of Content
- Introduction
- Types of Service Discovery Patterns
- What is a Service Registry ?
- Types of Service Registration Patterns
Introduction
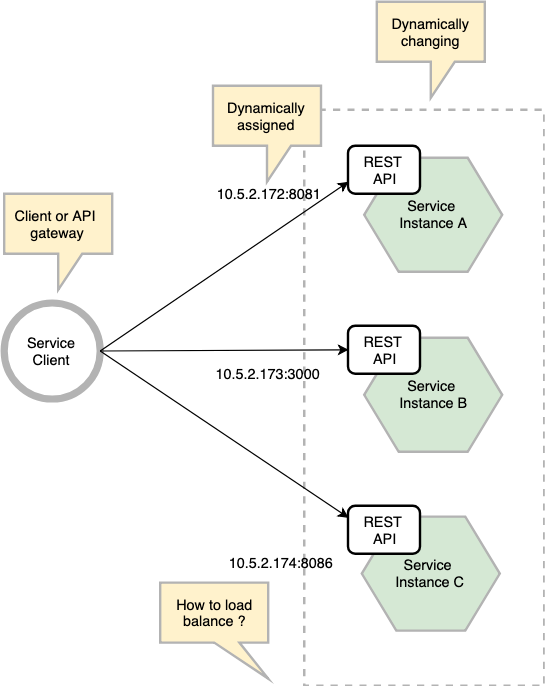
Services typically need to call one another. In a monolithic application, services invoke one another through language-level method or procedure calls. In a traditional distributed system deployment, services run at fixed, well known locations (hosts and ports) and so can easily call one another using HTTP/REST or some RPC mechanism. However, a modern microservice based application typically runs in a virtualized or containerized environments where the number of instances of a service and their location changes dynamically.
Let’s imagine that you are writing some code that invokes a service that has a REST API. In order to make a request, your code needs to know the network location (IP address and port) of a service instance. This can be easily implemented in a traditional system where locations are relatively static and a configuration file can hold all the network location. However, in a cloud-based microservice application, where service instances have dynamically assigned network locations and the number of instances changes dynamically because of autoscaling, failures and upgrades, it is difficult.
Types of Service Discovery Patterns
Client-Side Service Discovery
This is one of the solution to the problem discussed above. In client-side discovery, the client is responsible for determining the network locations of available service instances and load balancing requests across them. When making a request to a service, the client obtains the location of a service instance type by querying a Service Registry, which knows the location of all service instances. Client then uses a load-balancing algorithm to select one of the available service instances and makes a request.
The following diagram shows the structure of this pattern in details.
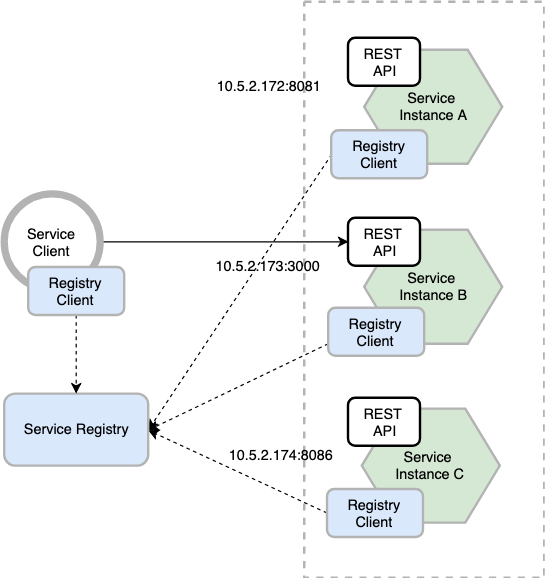
Netflix OSS provides a great example of the client-side discovery pattern. Netflix Eureka is a service registry. It provides a REST API for managing service-instance registration and for querying available instances. Netflix Ribbon is an IPC client that works with Eureka to load balance requests across the available service instances.
Client-side discovery has the following benefits:
- Fewer moving parts and network hops compared to
Server-Side Discovery - Since the client knows about the available service instances, it can make intelligent, application-specific load balancing decisions such as using hashing consistently
Client-side discovery also has the following drawbacks:
- This pattern couples the client to Service Registry
- Client-side service discovery logic has to be implemented for each programming language/framework used by your application
Server-Side Service Discovery
The other solution to service discovery problem stated above is the server-side discovery pattern. The following diagram shows the structure of this pattern.
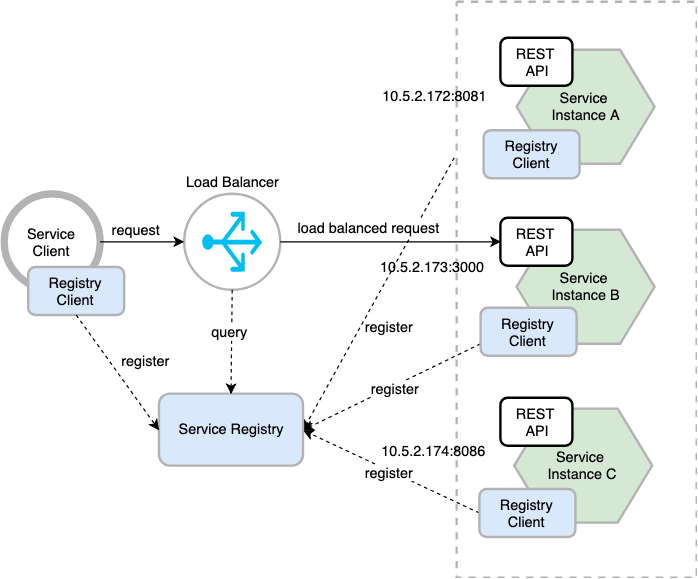
In a server-side service discovery, client makes a request to a service via a load balancer. The load balancer queries the service registry and routes each request to an available service instance. As with the client-side discovery, service instances are registered and deregistered with Service Registry.
The AWS Elastic Load Balancer (ELB) is an example of server-side discovery router. An ELB is commonly used to load balance external traffic from the internet. However, you can also used an ELB to load balance traffic that is internal to a virtual private cloud (VPC). A client makes request (HTTP or TCP) via the ELB using its DNS name. The ELB load balances the traffic among a set of registered Elastic Compute Cloud (EC2) instances or EC2 Container Service (ECS) containers. There isn’t a separate service registry. Instead, the service registry is built into the ELB itself.
Server-side discovery has following benefits:
- Details of discovery are abstracted away from the client. Clients simply make requests to the load balancer
- Discovery logic is not required to be implemented for each programming language and frameworks
Server-side discovery also has following drawbacks:
- Requires a load balancer by deployment environment. It is yet another highly available system component that you need to setup and manage.
What is a Service Registry ?
The service registry is a key part of service discovery. It is a database containing the network locations of service instances. A service registry needs to be highly available and up to date. Clients can cache network locations obtained from the service registry, this makes the application highly scalable. However, that information eventually becomes out of date and clients become unable to discover service instances. Consequently, a service registry consists of a cluster of servers that use a replication protocol to maintain consistency.
As mentioned earlier, Netflix Eureka is good example of a service registry. It provides a REST API for registering and querying service instances. A service instance registers its network location using a POST request. Every 30 seconds it must refresh its registration using a PUT request. A registration is removed by either using an HTTP DELETE request or by the instance registration timing out. As you might expect, a client can retrieve the registered service instances by using an HTTP GET request.
Other examples of service registries include:
- etcd – A highly available, distributed, consistent, key‑value store that is used for shared configuration and service discovery. Two notable projects that use etcd are Kubernetes and Cloud Foundry.
- consul – A tool for discovering and configuring services. It provides an API that allows clients to register and discover services. Consul can perform health checks to determine service availability.
- Apache Zookeeper – A widely used, high‑performance coordination service for distributed applications. Apache Zookeeper was originally a subproject of Hadoop but is now a top‑level project.
Also, as noted previously, some systems such as Kubernetes, Marathon, and AWS do not have an explicit service registry. Instead, the service registry is just a built‑in part of the infrastructure.
Types of Service Registration Patterns
As previously mentioned, service instances must be registered with and deregistered from the service registry. There are a couple of different ways to handle the registration and de-registration.
Self Registration
When using the self registration pattern, a service instance is responsible for registering and deregistering itself with the service registry. Also, if required, a service instance can send heartbeat requests to prevent its registration from expiring. If a service instance gracefully goes down, it should deregister itself. However, if it terminates abruptly, the service registry should deregister the instance in absence of heartbeat.
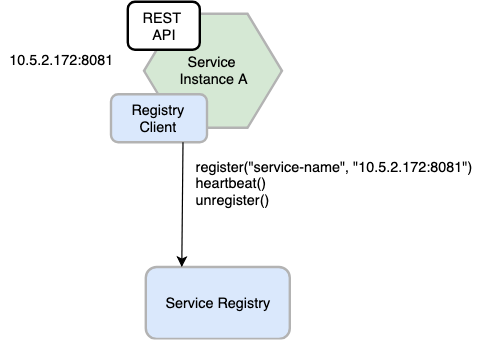
A good example of this approach is the Netflix OSS Eureka client. The Eureka client handles all aspects of service instance registration and de-registration. The Spring Cloud project, which implements various patterns including service discovery, makes it easy to automatically register a service instance with Eureka. You simply annotate your Java Configuration class with an @EnableEurekaClient annotation.
Third-Party Registration
When using the third-party registration pattern, service instances aren’t responsible for registering themselves with the service registry. Instead, another system component known as the service registrar handles the registration. The service registrar tracks changes to the set of running instances by either polling the deployment environment or subscribing to events. When it notices a newly available service instance it registers the instance with the service registry. The service registrar also deregisters terminated service instances. The following diagram shows the structure of this pattern.
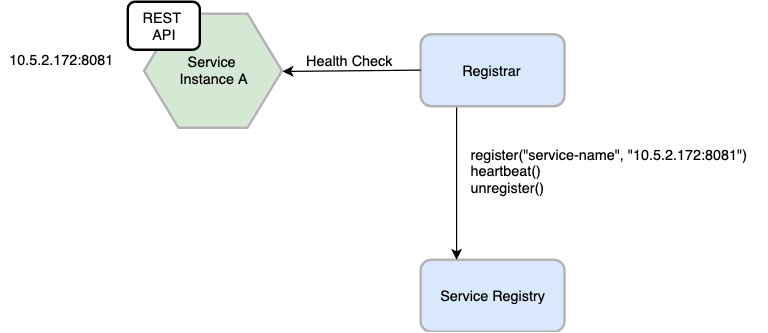
One example of a service registrar is the open source Registrator project. It automatically registers and deregisters service instances that are deployed as Docker containers. Registrator supports several service registries, including etcd and Consul.
The service registrar is a built‑in component of deployment environments. The EC2 instances created by an Autoscaling Group can be automatically registered with an ELB. Kubernetes services are automatically registered and made available for discovery.